
CADRE Laboratory for New Media
Inspiration
Google has captured the market for search engines in a way unlike any that came before it. It's created through a unique ranking algorithm they have developed known as PageRank, which works by assigning points to a page based upon the pages linking to it, as opposed to previous systems which used meta tags to organize relevance of search results. This is a much more objective tactic, and leaves the ranking entirely up to how many people reference a given site, rather than how well the designer of the site can describe it.
Visual Translation
A user enters a search query and the top ten google results are returned as ten nodes on the inner ring, with lines connecting them to the center. The pre-parser goes through and evaluates each page and draws all outgoing links as nodes within the second ring as second generation results.
When we get to the second generation, things may become more interesting. At this point the second generation results are evaluated for the outgoing links within those pages, and each will produce one of three results: (1) a link to a new page in the third ring ring indicated by a green curve, (2) a link to an already encountered page within the same generation of results indicated by a blue curve, and (3) a link to a previous generations results indicated by a red curve.
As nodes become interlinked and grow as a mesh, some nodes will become apparent as having more links directed towards them, which would indicate a higher pagerank. Nodes with a greater amount of green links traveling out from them indicates the amount of division their pagerank undergoes when applying it towards other pages.
Placement Method
Most web structures utilize a hierarchical placement graphing algorithm known as force-directed layout, in which nodes are evenly seperated from each other while parent/child nodes are pulled towards each other. While force-directed placement is ideal for dynamically arranged and constantly evolving data visualizations, it does not produce a symetrically aesthetic graph without further algorithmic modification.
Since processing works by rendering imagery through loop based programming, it is equally effective to utilize centralized circular placement rather than a force-directed model.
What are you trying to achieve?
The hope is that by viewing the outgoing and incoming links within a web of pages organized by topic, one can visually evaluate the results to find not only the most relevent ones, but also the pages that essentially decide which results are the most relevent. This may give an extra level of credibility to the most relevant sites when they are presented side-by-side with perhaps more familiar sites linking towards it. The inter-relations within and between generations will probably produce the most interesting results and trends, which directly reflect on the organization within pagerank.
Artistic Implications
The subject matter of this visualization tends to shift as the viewer begins to view it on a macro or micro level. It can be interpreted as the analysis of a particular queries results in terms of their instutitional status, or a reflection upon the network of corporate, academic, professional, and/or individuals pages that weave a meta-level trust network.
Google's PageRank is not available via their API, and word has it that it won't be. The fact that their crawlers and algorithm rely on pagerank as the heart of their dataset for sorting results makes it their interest to protect that information and prevent other sites from mining that data and using it for their own ends. The project then becomes a subversively analytical tool for investigating the relationships between outgoing and incoming links and the "social status" of the nodes from which they came.
Reference
Google Technology: brief description of pagerank sorting method.
Pigeon Rank: a more indepth and somewhat comical look at google's use of folksonomy.
Survey of Google's PageRank: an easy to understand explanation of the mathematics behind pagerank.
PageRank Explained: more complex explanation of pagerank with hypothetical examples of web structures.
TouchGraph GoogleBrowser: a visualization of web site interaction using force-directed placement.
Google Enabled Visual Search: an interesting force-directed visualization with the ability to manipulate the layout.
PageRank Decoder: an interactive visual modeler for calculating the interactions within pagerank.
Development Images

early crash results
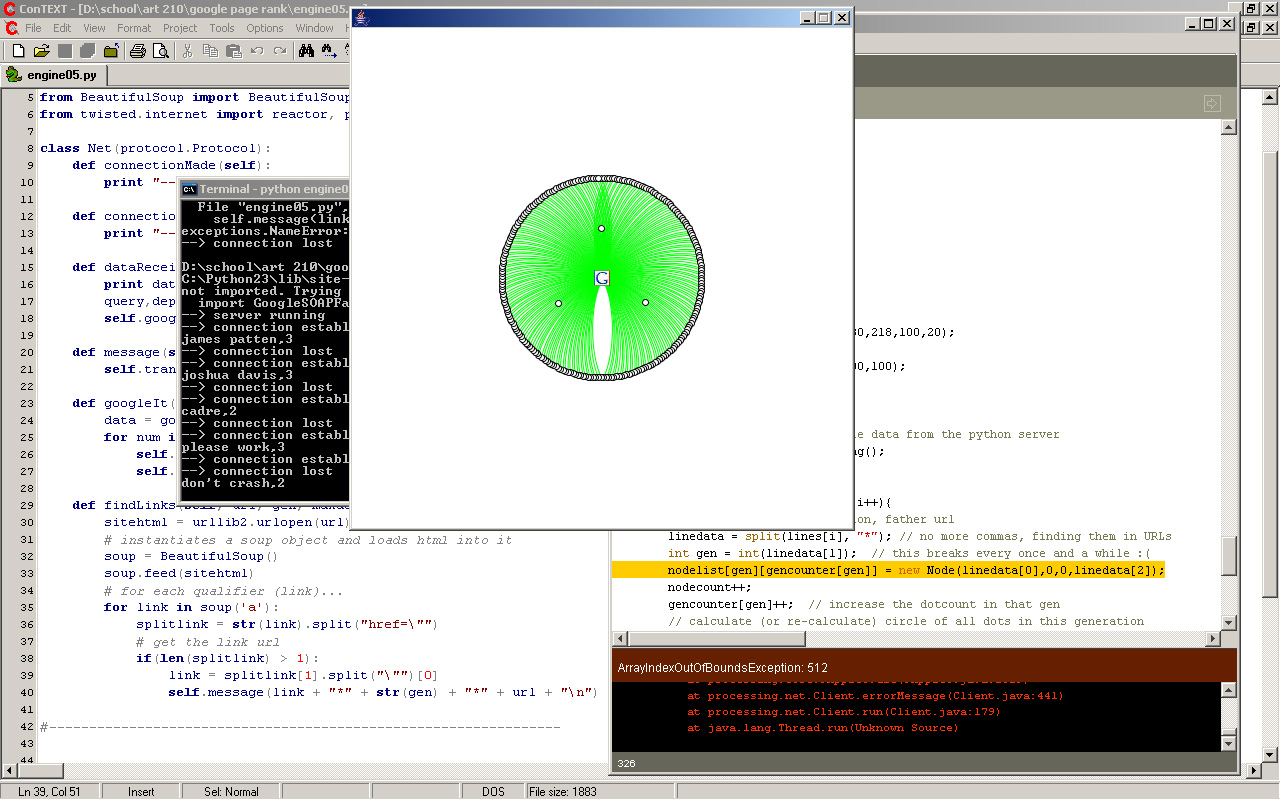
overflow of array, too many results

crashing is awesome
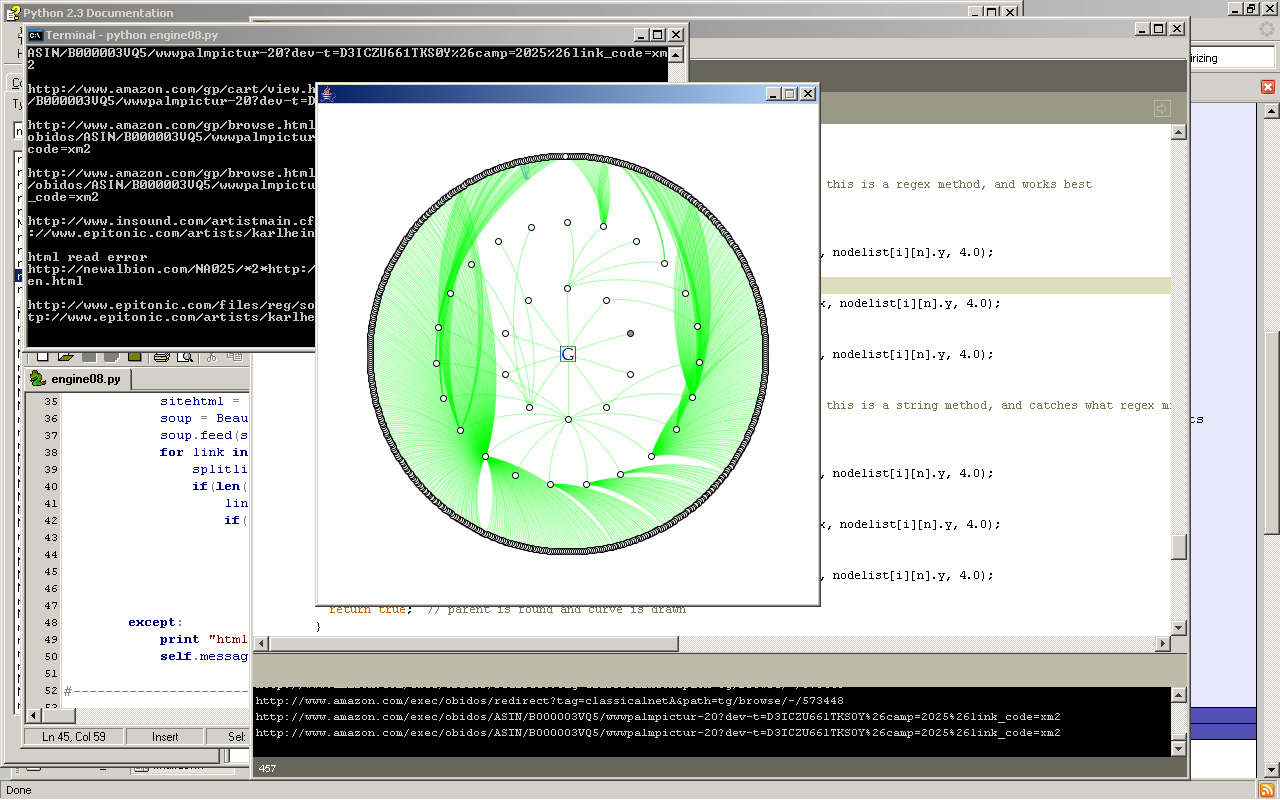
small amount of same dimension results
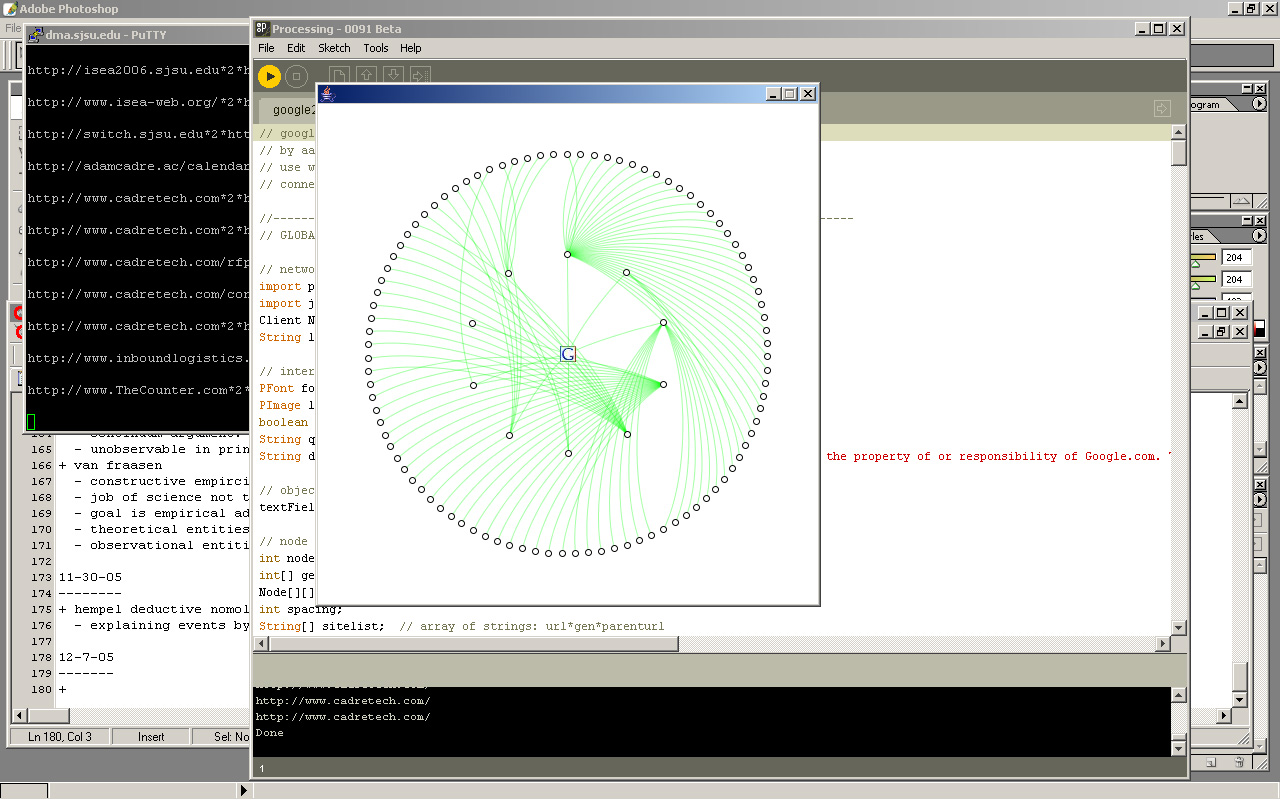
results to 2nd generation depth on "cadre" query
GoogleViz is in no way affiliated, sponsered, or in any way the property of or responsibility of Google.com. The Google logo is a trademark of Google Inc. Send any comments, questions, job opportunities, or cease and desist letters to asiegel@datadreamer.com.
[11/15] - 01 - [src]: basic interface/networking
[11/15] - 02 - [src]: added a query field
[11/15] - 03 - [src]: creating the node class
[11/15] - 04 - [src]: added depth, sends data to server
[11/15] - 05 - [src]: text field selection
[11/15] - 06 - [src]: disclaimer and node drawing
[11/15] - 07 - [src]: cursor checker, circular node placement
[11/15] - 08 - [src]: interface modifications
[11/15] - 09 - [src]: visits web site when node is clicked
[11/16] - 10 - [src]: begin drawing curves to parent
[11/16] - 11 - [src]: modifying curve properties
[11/16] - 12 - [src]
[11/16] - 13 - [src]
[11/16] - 14 - [src]: officially reaches kludge state
[11/16] - 15 - [src]
[11/16] - 16 - [src]
[11/16] - 17 - [src]
[11/17] - 18 - [src]: added visited site checker
[11/17] - 19 - [src]
[11/17] - 20 - [src]: saved from kludgeness
[11/17] - 21 - [src]: "uh oh hot dog!" error checker
[11/20] - 22 - [src]
[11/20] - 23 - [src]: improved error checker
[11/21] - 24 - [src]: adding text to nodes
[11/22] - 25 - [src]: radial rotation of text
[11/22] - 26 - [src]: rollover effect for node text
[11/25] - 27 - [src]: successful local connect, returns to maximum dimension
[12/05] - 28 - [src]: successfully connects to server, doesn't work via web
Python Crawler Progress:
[10/19] - 01: connects to processing, returns google top 10 results
[11/15] - 02: gets depth data from processing, ignores for now
[11/15] - 03: returns depth data about link to processing
[11/15] - 04: fixed parent reference return
[11/15] - 05: follows top ten results and returns all links on each page
[11/16] - 06: added sleep of 1/10 of a second to slow web crawling
[11/17] - 07: returns end of data signal to change processing status
[11/25] - 08: runs recursively to maximum specified depth
Preliminary Processing Research:
[10/17] - [src] - circular placement of nodes
[10/18] - [src] - multi-radius circular placement
[10/19] - [src] - connects to server, instantiates objects for returned results
[10/20] - [src] - circular placement of top 10 results
[10/20] - [src] - draws paths from top 10 results to center icon
[10/20] - [src] - added text field to submit dynamic search query
[10/21] - [src] - nodes are clickable to visit pages they represent
[10/21] - [src] - aesthetic integration of logo
[10/22] - [src] - generation depth field and field selection
[11/02] - [src] - cubic bezier control point calculator
[11/15] - [src] - sends depth information to python server along with query
[11/15] - [src] - madness
[11/15] - [src] - more madness
[11/15] - [src] - reaches critical mass, necessitates a fresh start
Preliminary Python Research:
[08/31] - spider 01: visits the first link of a given site, runs recursively until exhausted
[08/31] - spider 02: launches a thread of itself for each link encountered
[10/11] - search 01: urlopen google query, returns 403 forbidden error
[10/11] - search 02: mechanize google query, returns 403 forbidden error
[10/11] - search 03: mechanize troubleshooting, still errors
[10/11] - search 04: yet another way to get a 403 error
[10/11] - search 05: mechanize still sucks
[10/11] - search 06: doing things properly with pygoogle and the Google API
[10/11] - search 07: returns top 10 google results and finds links on each page
[10/19] - server 01: simple server
[10/19] - server 02: improved server
Video:
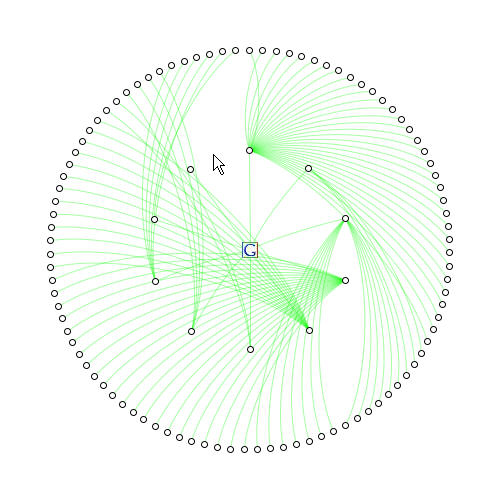
A query of "cadre" to a depth of 2. [6.1mb]
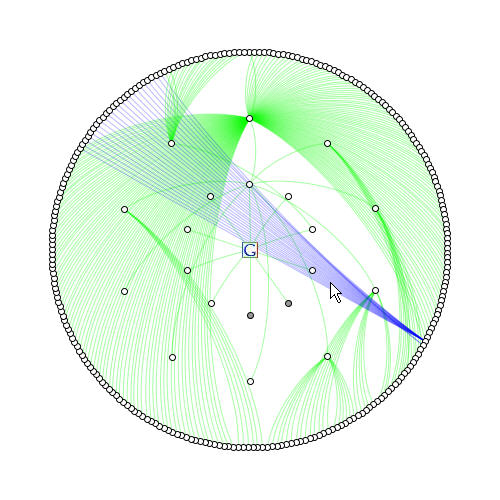
A query of "datadreamer" to a depth of 3. [17.6mb]